
With the election just a few days away, Nate Silver and his blog FiveThirtyEight have been increasingly in the news. I've been an enthusiastic reader since the 2008 election, when Silver correctly predicted the outcome in every senate race, and the general election result in 49 of 50 states.
Silver describes his prediction methodology on his blog. I've implemented a rough version of it in Python, with placeholders for things I haven't done yet. Code and polling data are available on github (vedant/election-prediction.git). Polling data are scraped from Real Clear Politics. Try modifying and augmenting it to generate your own projections.
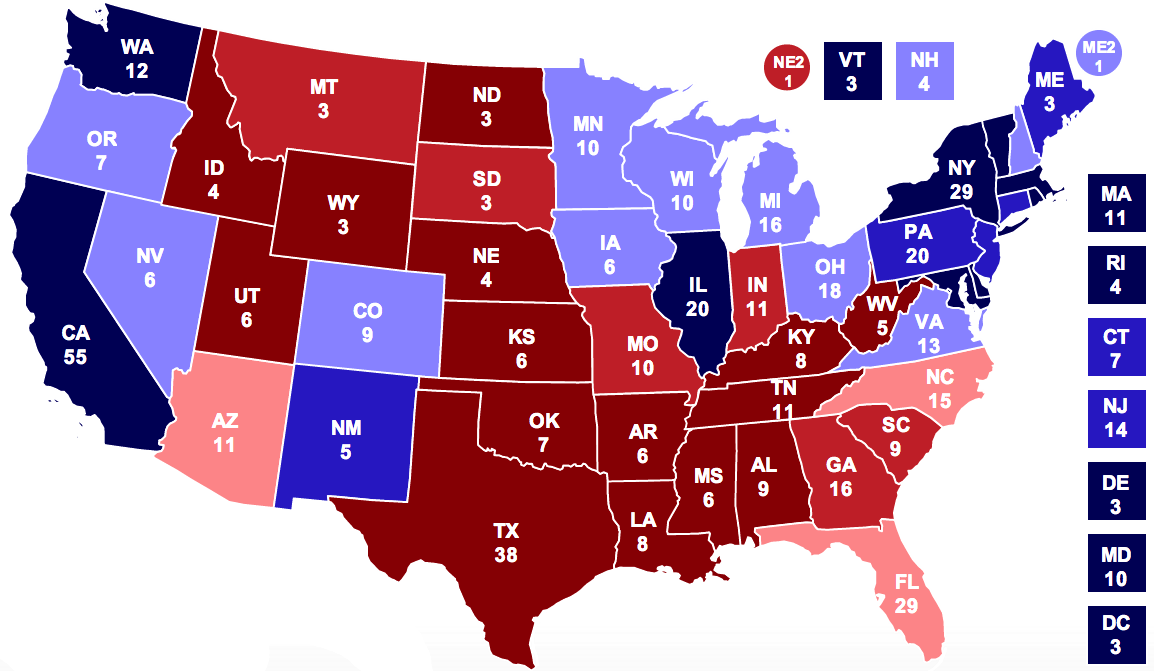
This implementation predicts 303 electoral college votes for President Obama, to 235 for Governor Romney, and generated the electoral college map below. This is close to Silver's current projection of 305 to 23.
The model implemented here gives an exponentially decaying weight to older polls, but doesn't consider poll sample size or historical pollster ratings. I expect that neither of these is especially important when using the RealClearPolitics polling data, which seems to include only major polls. The implementation also drops historically unreliable pollsters, and provides for dropping partisan polls and making adjustments to polls that have historically leaned to one side.
There is currently no trendline adjustment to account for the recent propensity of the electorate, and no likely voter adjustment or non-poll data, all of which are included in Nate Silver's model.
The result of this implementation is probably only close to Nate Silver's actual methodology because there is extensive polling data for the presidential election. I imagine the more sophisticated model components only play a significant role in Nate Silver's model when polling data is more sparse and less consistent.